RAG (Retrieval-Augmented Generation) is changing the game in Natural Language Processing (NLP).
It's like having a super-smart assistant that can find the right information and give you the perfect answer.
In our previous article, we have already discussed about the overview of RAG.
This article will explore the RAG pipeline's structure, how to build one, ways to enhance RAG systems and its applications in knowledge-rich NLP tasks.
By the end, you'll clearly understand how RAG is reshaping NLP, making complex tasks more accessible and effective.
The Structure of a RAG Pipeline
In recent years, the integration of advanced technologies like machine learning and natural language processing has led to remarkable advancements in AI models.
One such innovative approach is the Retrieval-Augmented Generation (RAG) pipeline.
RAG combines the power of large language models (LLMs) with external knowledge sources to enhance the model's understanding and generate more contextually relevant responses.
Let's explore the structure of a typical RAG pipeline:
1. Leveraging External Knowledge
One of the key features of RAG is its ability to access external knowledge sources, such as databases, to enrich its understanding.
By doing so, the model can incorporate information beyond what is encoded in its weights.
2. Retriever Component
RAG utilizes a retriever component to fetch relevant contexts from external sources. This component plays a crucial role in augmenting the knowledge base of the LLM.
The retriever can use various strategies for retrieval, depending on the application's requirements:
Queries are embedded using models like BERT to generate dense vector embeddings. This allows for semantic similarity-based search or traditional methods like TF-IDF for sparse embeddings.
Constructs a knowledge base from extracted entity relationships within the text. While precise, it may require exact query matching, which could be limiting.
Offers structured data storage and retrieval but may lack the semantic flexibility of vector databases.
3. Combining Graph and Vector Databases
Some experts suggest combining the strengths of both databases by indexing parsed entity relationships with vector representations in a graph database.
This hybrid model could potentially offer more flexible information retrieval capabilities.
4. Filtering and Ranking
After retrieving relevant candidates, additional filtering and ranking layers can be applied.
These layers help in further refining the candidates based on business rules, personalization for the user, current context, or response limits.
5. Summarising the RAG Process
Internal dataset conversion into vectors and storing in a vector database.
The user provides a natural language query.
The retrieval mechanism scans the vector database to identify semantically similar segments to the user's query.
Chosen data segments from the database are combined with the user's query, creating an expanded prompt.
The expanded prompt, filled with added context, is given to the LLM, which generates the final, context-aware response.

Image Source: Retrieval-Augmented Generation
RAG represents a significant advancement in AI, enabling models to access and utilise external knowledge to enhance their understanding and generate more relevant responses.
As technology continues to evolve, we can expect further refinements and innovations in the RAG pipeline, opening up new possibilities for AI applications across various domains.
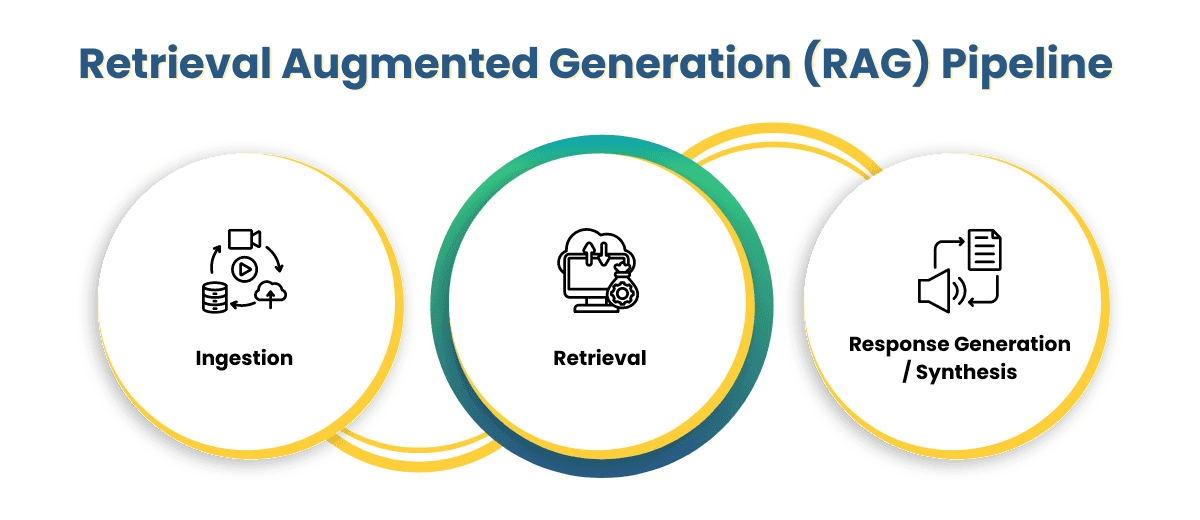
Building a RAG Pipeline
The process of building a Retrieval-Augmented Generation (RAG) pipeline involves several key steps.
In this section, we'll explore these steps and how they contribute to the overall functionality of a RAG system.

Image Source: RAG Pipeline
1. Ingestion
1.1 Chunking
Ingestion is pivotal in enhancing the accuracy and relevance of retrieved information.
One of the key techniques used in ingestion is chunking, which involves breaking down prompts or documents into smaller, manageable segments or chunks.
The size of these chunks is critical, as it impacts the precision and comprehensiveness of the retrieval process.
In Retrieval-Augmented Generation (RAG), chunking is particularly important for encoding each chunk into an embedding vector for retrieval.
Smaller, more precise chunks help in achieving a finer match between the user's query and the content, thereby improving the accuracy of the retrieved information.
On the other hand, larger chunks may include irrelevant information, leading to noise and reduced retrieval accuracy.
Choosing the right chunk size is essential in RAG. It should be small enough to ensure relevance and reduce noise, yet large enough to maintain the context's integrity.
There are several methods for determining the chunk size:
1.1.1 Fixed-size chunking
This method involves deciding the number of tokens in a chunk and whether there should be overlap between them.
Overlapping chunks ensure minimal semantic context loss but require more computational resources.
Here's an example of how to do fixed-sized chunking with LangChain:
text = "..." # your text
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator = "\n\n",
chunk_size = 256,
chunk_overlap = 20
)
docs = text_splitter.create_documents([text])
1.1.2 “Content-aware” Chunking
"Content-aware" chunking refers to methods that consider the nature of the content being chunked to apply more advanced chunking techniques.
For example, one method is sentence splitting, where text is divided into sentences.
There are different approaches to sentence splitting, including:
Naive splitting: This approach simply splits sentences by periods (".") and new lines. While quick and easy, it may not handle all cases correctly.
text = "..." # your text
docs = text.split(".")
NLTK: NLTK, short for Natural Language Toolkit, is a widely-used Python library designed for handling human language data. It provides a sentence tokenizer to split text into sentences, creating more meaningful chunks.
text = "..." # your text
from langchain.text_splitter import NLTKTextSplitter
text_splitter = NLTKTextSplitter()
docs = text_splitter.split_text(text)
spaCy: Another powerful Python library for NLP tasks, spaCy offers a sophisticated sentence segmentation feature for dividing text into sentences, preserving context better in the resulting chunks.
text = "..." # your text
from langchain.text_splitter import SpacyTextSplitter
text_splitter = SpaCyTextSplitter()
docs = text_splitter.split_text(text)
1.1.3 Recursive Chunking
Recursive chunking is a method to divide the text into smaller parts in a step-by-step way, using certain separators.
If the first try doesn't give chunks of the right size or structure, it tries again on those chunks with a different separator until it gets the desired result.
This means the final chunks might not all be the exact same size, but they'll aim to be similar.
Here's how you can use recursive chunking with LangChain:
text = "..." # your text
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 256,
chunk_overlap = 20
)
docs = text_splitter.create_documents([text])
1.1.4 Specialized chunking
Specialized chunking is used for structured and formatted content like Markdown and LaTeX. These methods help preserve the original structure of the content during chunking.
Markdown: Markdown is a simple markup language used for text formatting. By understanding Markdown syntax (like headings and lists), you can divide content based on its structure, creating more meaningful chunks.
from langchain.text_splitter import MarkdownTextSplitter
markdown_text = "..."
markdown_splitter = MarkdownTextSplitter(chunk_size=100, chunk_overlap=0)
docs = markdown_splitter.create_documents([markdown_text])
LaTeX: LaTeX is a tool for preparing documents, commonly used for academic and technical papers.
By understanding LaTeX commands, you can divide the content into meaningful sections that respect the logical organisation (like sections and equations), making the results more accurate and relevant.
from langchain.text_splitter import LatexTextSplitter
latex_text = "..."
latex_splitter = LatexTextSplitter(chunk_size=100, chunk_overlap=0)
docs = latex_splitter.create_documents([latex_text])
1.2 Embeddings
After chunking your prompt appropriately, the next step is to embed it.
Embedding prompts and documents in RAG means transforming both the user's query (prompt) and the documents in the knowledge base into a format that can be effectively compared for relevance.
This step is crucial for RAG to find the most relevant information from its knowledge base in response to a user query.
Here's how it usually works:
There's a choice between using dense or sparse embeddings, each with its own benefits:
1.2.1 Sparse embedding (e.g., TF-IDF)
Ideal for keyword matching between the prompt and documents, important for applications where keyword relevance is key.
It's less computationally intensive but may not capture the deeper meanings in the text.
1.2.2 Semantic embedding (e.g., BERT or SentenceBERT)
These embeddings are well-suited for the RAG use case.
BERT: Good at capturing contextual nuances in both documents and queries, requiring more computational resources but offering more semantically rich embeddings.
SentenceBERT: Great for scenarios where sentence-level context and meaning matter.
It balances BERT's deep contextual understanding with the need for concise, meaningful sentence representations, making it often the preferred choice for RAG.
2. Retrieval
Let's explore three types of retrieval methods: standard, sentence window, and auto-merging.
Each method has its own advantages and disadvantages, and the best choice depends on the specific needs of the RAG task.
Factors like the dataset, query complexity, and the desired balance between specific and contextual responses all play a role in determining the most suitable approach.
2.1 Standard/Naive Approach
As shown in the image below, the standard pipeline uses the same text chunk for both indexing/embedding and output synthesis.

Image Source: RAG
2.2 Sentence-Window Retrieval
Sentence-Window Retrieval, also known as Small-to-Large Chunking, breaks down documents into smaller parts like sentences or small groups of sentences.
This method separates the embeddings for retrieval tasks (stored in a Vector DB) into smaller chunks. However, for synthesis, it adds back the context around the retrieved chunks.

Image Source: Sentence-Window Retrieval Pipeline
2.3 Auto-merging Retriever / Hierarchical Retriever
Auto-merging retrieval is a way to combine information from different sources or parts of text to give a more complete answer to a question. It's helpful when no single source has all the information needed.
It works by grouping smaller pieces of information into larger groups. Here's how it works:
- Create a hierarchy of smaller pieces linked to larger ones.
- If the group of smaller pieces linked to a larger one is big enough (based on a similarity measure like cosine similarity), then combine them into the larger group.
- Finally, retrieve the larger group for a more complete answer.
The below image shows how auto-merging retrieval can work without getting a bunch of broken pieces, which would happen with a basic approach.

Image source: Auto-merging retrieval
Using smaller chunks in the naive approach would make the fragmentation even worse, as demonstrated below.

3. Response Generation / Synthesis
In the last step of the RAG process, the model creates responses for the user.
It combines the information it found with what it already knows to make responses that make sense in context.
This means it uses insights from different sources to create accurate and relevant answers that match what the user asked.
The model must strategically arrange the information in the input sequence for better performance.
Improving RAG Systems
To further improve the effectiveness and performance of RAG systems, several structured methods have been developed, each offering unique approaches and benefits.
In this section, we will explore three key methods along with their practical implementations and guides.
1. Re-ranking Retrieved Results
One fundamental method to enhance RAG systems is through the use of a Re-ranking Model. This approach involves refining the initial retrieval results by prioritising more relevant content.
Deep models like MonoT5, MonoBERT, and DuoBERT are examples of models that can be used as re-rankers.
2. FLARE Technique
Following the re-ranking process, the FLARE methodology can be employed.
This technique dynamically queries the internet or a local knowledge base whenever the confidence level of a segment of the generated content falls below a specified threshold.
Unlike conventional RAG systems, which query the knowledge base only at the beginning, FLARE continuously updates and refines the content throughout the generation process.
3. HyDE Approach
The HyDE technique introduces an innovative concept of generating a hypothetical document in response to a query.
This document is then converted into an embedding vector, which is used to identify a similar neighbourhood within the corpus embedding space.
This approach retrieves analogous real documents based on vector similarity, enhancing the contextual relevance of generated responses.
Each of these methods provides a distinct way to improve RAG systems, leading to more precise and contextually appropriate outcomes.
By incorporating these methods into RAG systems, developers and researchers can enhance the overall performance and effectiveness of AI-generated content, ultimately improving user experiences and outcomes.
RAG for Knowledge-Intensive NLP Tasks
RAG was first introduced in 2021 when LLMs were not as well understood and Seq2Seq models were very popular.
Its purpose was to help with tasks that require a lot of knowledge, which humans can't do without using outside information.
Pretrained language models have a lot of information stored in them, but they are not good at accessing and using this knowledge.
This made language model-based systems perform much worse than specialized methods that extract information.
In simpler terms, researchers were trying to find an easy and effective way to add more knowledge to pre-trained models.

Images sources: RAG
1. How can RAG Help?
The idea behind RAG is to help a pre-trained language model access and use knowledge better.
It does this by connecting the model to a memory store, which is usually a collection of documents or text data that the model can search through.
With this setup, the model can retrieve relevant information from the memory store while generating output.
This not only gives the model more context but also lets us, the users or trainers of the model, see how it solves problems.
In contrast, the workings of a pre-trained language model are mostly hidden from us.

The model mentioned above is fine-tuned using this RAG setup.
This RAG strategy is not just for improving factuality during inference but also serves as a way to connect pre-trained language models with external information sources.
2. RAG Setup
In simpler terms, RAG starts by taking an input sequence (the prompt) and using it to find relevant documents (text chunks) that will help generate a response.
To find these documents, the authors use a model called dense passage retrieval (DPR), which is trained to understand queries and documents.
For generating the response, they use a model called BART, which is trained to understand and produce text.
Both the document retrieval and response generation steps use pre-trained models, so further training is optional.

In simpler terms, the data for RAG in above comes from Wikipedia and is divided into chunks of 100 words each.
The size of these chunks is a variable that needs to be adjusted based on the specific use.
Each chunk is turned into a vector using DPR's pre-trained document encoder.
These vectors are then used to create an index for quick and efficient searching, allowing RAG to find and use the right chunks when given a piece of text as input.
3. Training with RAG
The dataset for training the RAG model has pairs of questions and answers. To train the model, we start by turning the question into a vector using DPR's query encoder.
Then, we find the K most similar text chunks in the document index by comparing this vector with others.
Next, we combine a text chunk with the question and give this combined input to BART to get the answer.

In simpler terms, when using the model with BART to generate text, it can only take one document at a time.
So, when predicting the text, we consider the top K documents and predict the text distribution for each document.
This means we run BART separately for each document, and then combine the outputs based on the probability of each document being correct (which is based on how similar the document is to the input query).
There are two ways suggested to combine these outputs:
- RAG-Sequence: Uses the same document for each word in the output.
- RAG-Token: Uses a different document for each word in the output.
During actual use (inference), we can choose either method using a modified form of beam search.
To train the model, we use a standard language modelling approach to maximize the likelihood of the correct output.
Importantly, only the query encoder and the text generator are trained in the RAG approach, while the document encoder remains fixed.
This avoids the need to rebuild the search index for documents, which would be costly.
4. How does it Perform?
The RAG method is tested on many NLP tasks that require a lot of knowledge. They compare RAG to two other methods:
These predict an answer by selecting a piece of text from a retrieved document.
These generate an answer without using any retrieval process.

As seen in the tables, RAG performs exceptionally well on open-domain question-answering tasks, beating both extractive and Seq2Seq models.
It even surpasses models that use a cross-encoder-style retriever for documents. Unlike extractive methods, RAG can answer questions that are not directly in the retrieved documents.
RAG combines the flexibility of closed-book approaches with the performance of open-book retrieval-based approaches.
For abstractive question answering, RAG also performs nearly as well as the best methods.
While baseline techniques have access to a perfect passage containing the answer, RAG often generates more specific, diverse, and factually accurate responses, even when the necessary information is not readily available.
Conclusion
The Retrieval-Augmented Generation (RAG) pipeline represents a significant advancement in NLP technology, offering enhanced capabilities for generating contextually relevant and informative responses.
By understanding its structure, building process, and methods for improvement, developers and researchers can harness the power of RAG to revolutionise natural language processing applications.