- 1st Oct, 2023
- Rinkal J.
Introduction to K-Means Clustering
In the field of machine learning, one of the key objectives is to achieve accurate predictions. These predictions can be achieved through various learning algorithms,...
Keep Reading8th Mar, 2021 | Jay D.

Take a ride back to your childhood and trace the path of the way you started speaking your mother tongue, or begin understanding colors and pictures. When you first started speaking, there could have been a lot of pronunciation error, misspelling, inaccuracies and jumbling while speaking. Normally, at the age of 2-3, a child develops speaking in its very simpler form or phrases. Later after an evolution of a certain age, a child’s mind has learned to speak complex words and sentences.
The mind has trained itself to learn from experience and each time its learning increases depending on the availability of words, observation and proper feedback. Imagine simulating the above natural phenomenon artificially and that’s where "Artificial Neural Networks (ANN)" are born.
The human brain processes billions of interconnection among the neurons which form its own biological network. These connections are formed or altered or removed once our brain learns. This is quite a repetitive process as far as learning is considered.
ANN is a replica of one’s natural brain and can learn any specific output by self-learning. The different architecture of neural networks finds its application across almost every sector like Real Estate Prediction, Speech Recognition, Machine Translation, Photo Tagging and Autonomous Driving etc.
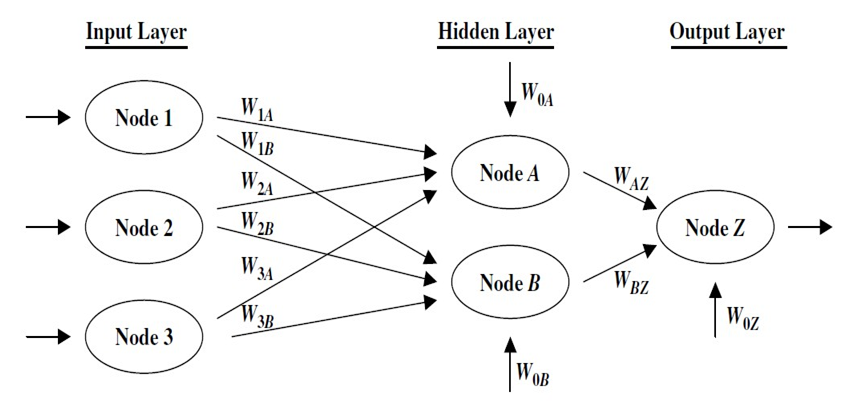
ANN comprises three layers: input, hidden and output. Input and output layer is singular, unlike the hidden layer.
The number of hidden layers to be chosen is decided by how complex the problem is or by experiments. ANN assigns random weights and random biases to an input layer to train on its own during the first iteration of training.
The activation function is presented in each layer of the network and it can be any non-linear mathematical function like sigmoid or ReLu. It is needed to make networks learn complex patterns in the data.
It's very obvious that at the end of the first iteration, ‘predicted output’ would not fall in the vicinity of ‘true output’. It learns the error between predicted output and an actual output.
It back propagates the error in the network by updating the weights and biases in the next iteration. The aim is to iterate through forward propagation followed by back propagation until the error is within the acceptable thresholds.
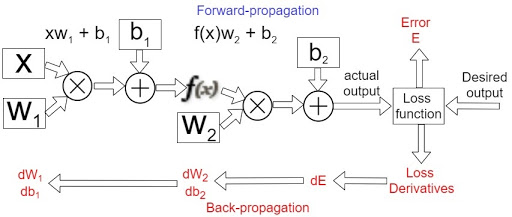
The cycle of applying ANN is highly iterative in nature. It involves experimenting with an idea iteratively, and to make it more efficient, we split our dataset into different sets like training set, validation set and testing set.
The core idea behind splitting is to first train the data available in ‘training set’, ANN learns from the data present in this set. Later to understand how well does ANN generalize on a problem, its performance is tested on a ‘testing set’, which was absent in the training set.
The ‘validation set’ serves the purpose of tuning hyper-parameters on a trained model. There is a key difference between parameters and hyper-parameters of Deep Learning.
The parameters of ANN are weights and biases. Both weight and bias are not in our control, as it gets updated by the network itself depending on the learning. However, the hyper-parameters are the ones used to control the learning process.
A typical example of hyper-parameter could be choosing the number of hidden layers, activation function, learning rate or number of iterations. Calibration of hyper-parameters results in minimizing a loss function and yielding a better performance.
The ANN model always faces the issue of "bias variance" trade-off.
Imagine that the performance of the model is very bad on the "training set", it indicates that the network is "under-trained."
If an "under-fit" model performs poorly on the data it knows, then it would always perform worse on the "test-set" i.e the unknown data. This is referred to as "under-fitting" or "bias."
On the contrary, consider that the model learns everything so perfectly from the "train-data", that it gives absolute zero error (ideally) on a "train-set". This looks good at first sight, but if it has learned so much from the train data, then it would not give accurate results on a "test-set."
As it has ‘over-learn’, it can’t generalize well on the unseen data. This leads to a problem referred to as "over-fitting" or a "variance."
This leads us to an important conclusion, that neither our model should be too simple that it "under-fits" the data nor too complex that it ‘over-fits’ the data. This calls for a "bias variance trade-off", in which we try to achieve balance between both.
The simulated human brain works on the principle of our biological brain and one important thing to note here is that ANN is self-learning, adjustable and complex structure. One more advantage of ANN is like our brain, it stores all the information in its own network, instead of a database. So, its working performance is unaffected by any loss of data. According to Dr. Andrew Ng, globally recognized leader in A.I, "A.I is the new electricity of the 21st century, which will transform every industry and create huge economic value."
References:


Get insights on the latest trends in technology and industry, delivered straight to your inbox.






